While olfaction is central to how animals perceive the world, this rich chemical sensory modality remains largely inaccessible to machines. One key bottleneck is the lack of diverse, multimodal olfactory data collected in natural settings. We present New York Smells, a large-scale dataset of paired image and olfactory signals captured in-the-wild. Our dataset contains 7,000 smell-image pairs from 3,500 distinct objects across diverse indoor and outdoor environments, and it is 70× larger than prior olfactory datasets. We create benchmarks for three tasks: cross-modal smell-to-image retrieval, recognizing scenes, objects, and materials from smell alone, and fine-grained discrimination between grass species. Models trained on raw olfactory signals outperform widely-used hand-crafted features, and visual data enables learning of olfactory representations.

We collect a diverse dataset of paired sight and olfaction by visiting many locations within a city and recording a variety of materials and objects in different scenes. Our dataset contains 7,000 olfactory-visual samples from 3,500 objects across 60 sessions.

We walk through New York City and capture paired olfaction and visual signals using a camera mounted to a Cyranose 320 electronic nose on a custom 3D-printed sensor rig. We also capture depth, temperature, humidity, and ambient VOC concentrations.


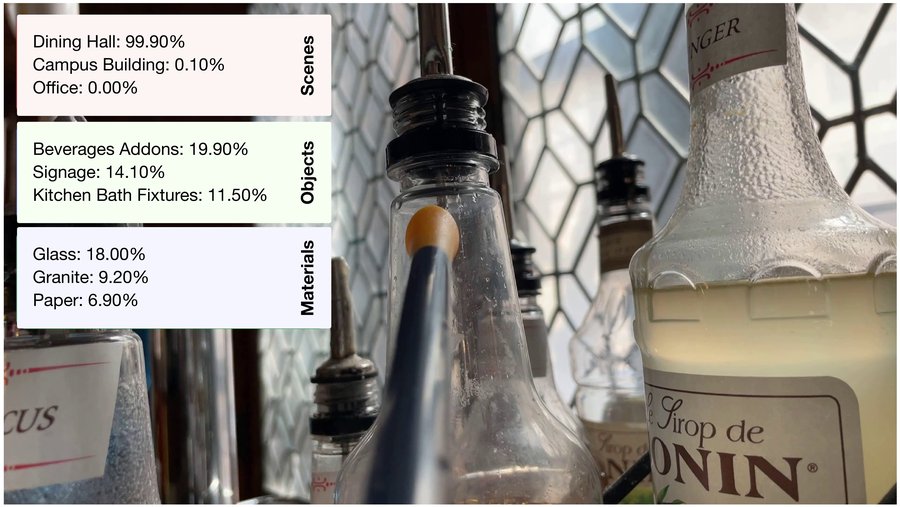








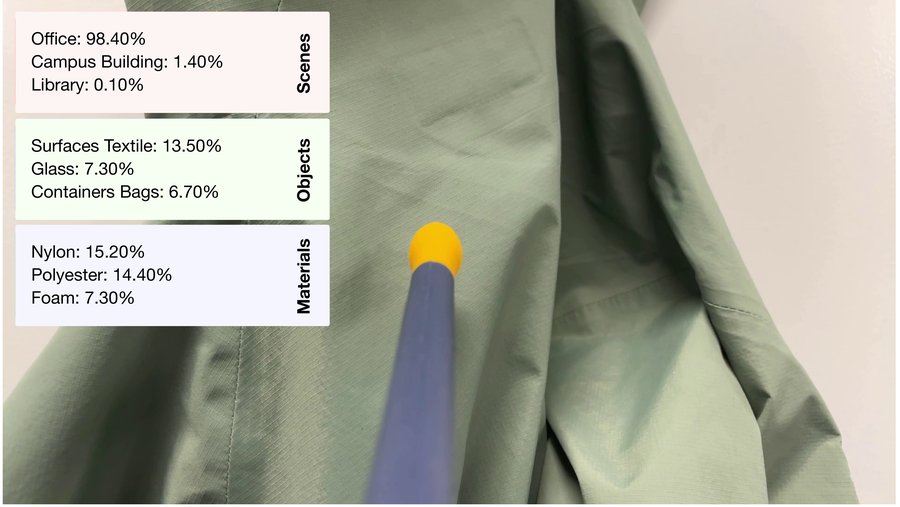
We show predictions from linear probing on the smell encoder. Models trained on raw olfactory signals significantly outperform hand-crafted features at recognizing scenes, objects, and materials from smell alone. Predictions are from smell alone. Images are shown for visualization purposes only.

Given a query smell, we retrieve the closest matching images in embedding space. Our model learns meaningful cross-modal associations between smell and sight.
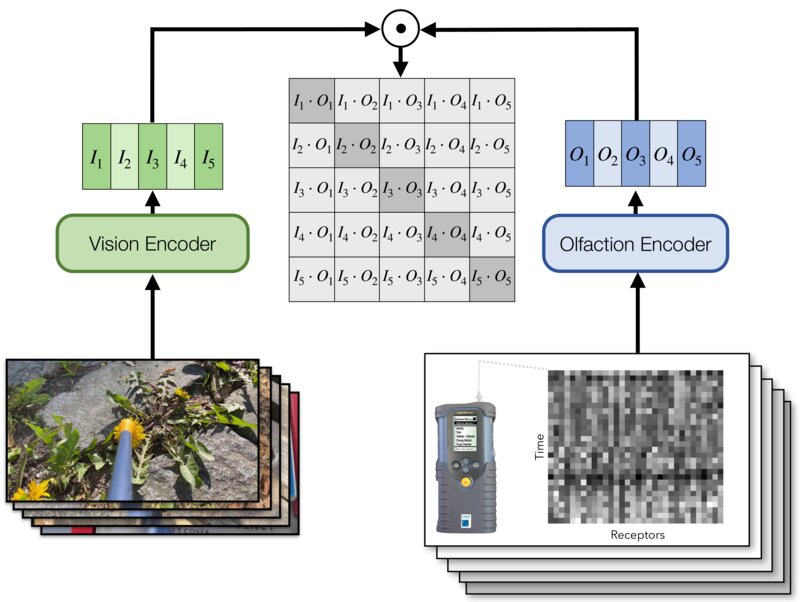
We train general-purpose olfactory representations using contrastive learning between smell and vision. The model learns to align co-occurring visual and smell signals, enabling cross-modal associations.

View of the Upper West Side skyline from Central Park, New York City.
@article{ozguroglu2025smell,
title={New York Smells: A Large Multimodal Dataset for Olfaction},
author={Ozguroglu, Ege and Liang, Junbang and Liu, Ruoshi and Chiquier, Mia and DeTienne, Michael and Qian, Wesley Wei and Horowitz, Alexandra and Owens, Andrew and Vondrick, Carl},
journal={arXiv preprint arXiv:2511.20544},
year={2025}
}